案发背景
小G找到我说,发生怪事,他说在表里改了某个字段(master_cluster_status),改完当场是成功的改完之后过了几分钟又变回去,重复了几次都没用,最终还是变回 failed,看update_time,现象是过几分钟更新,感觉是机器动作,不是人为。
用户在我们这里搭建的容灾,我们调用华为api实现,同时也会定时去华为云拉取特定状态回写到自己表
处理过程
于是我很好奇,写程序那么多年,虽然出现过奇怪的事情,但从没灵异案件出现,肯定是bug~~
我让小G找到对应ORM对象(java和mysql绑定的对象)查看master_cluster_status在哪些方法使用过,重点观察定时任务。分析约莫半个小时,确认所有入口,都不会把master_cluster_status设置成failed 搜索failed这个枚举的引用,也排除是程序里有逻辑主动设置
继续分析
思来想去,这时想起之前有处理过长事务问题,事务结束才把数据写入表里,于是我猜测应该是以下这种可能情况
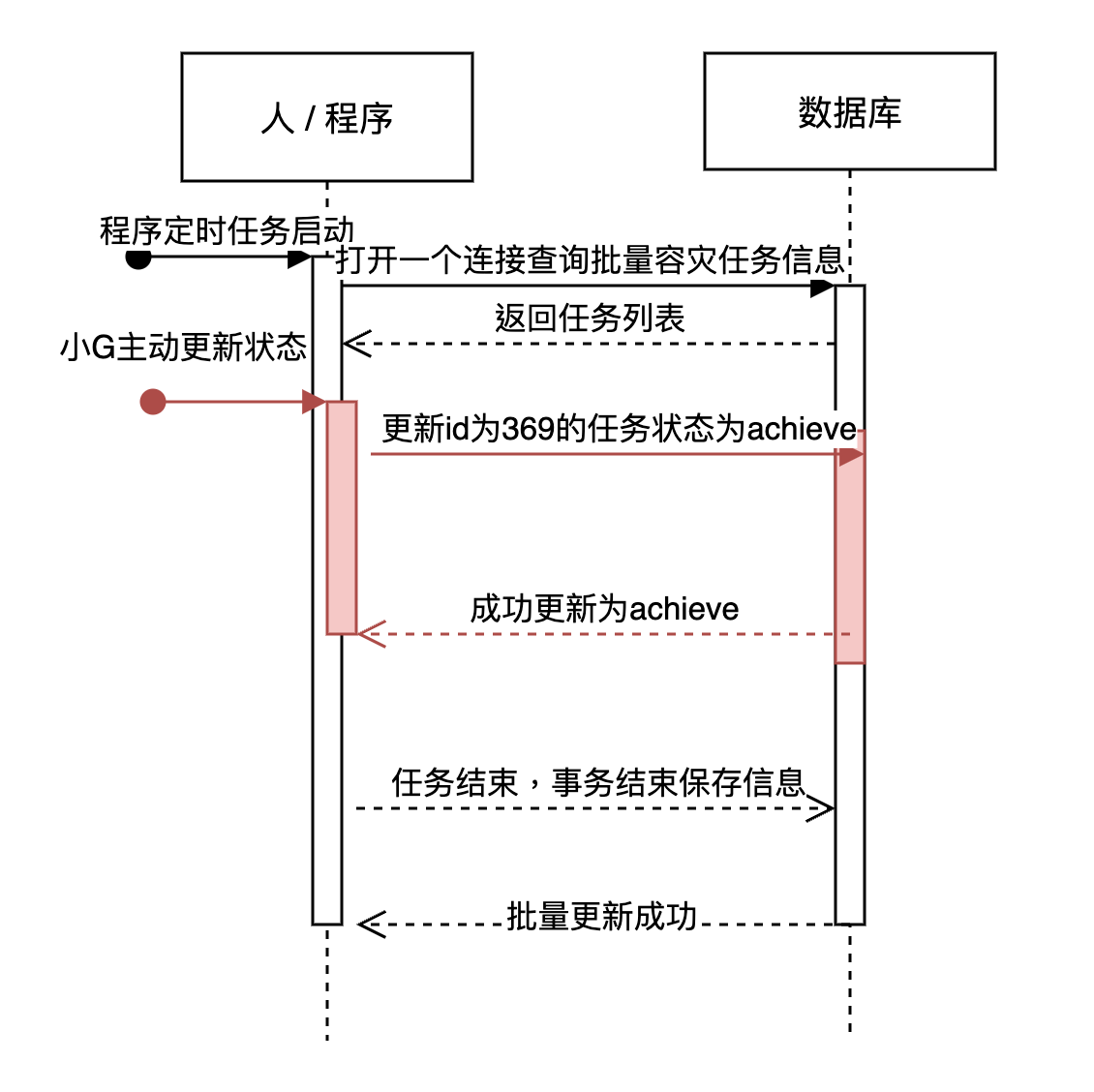
也就是说,很可能小G每次更新操作,都是定时任务启动了,等定时任务结束,定时任务回写
小伙伴好奇,没地方修改这个值,为啥会把failed写入呢,原因就出在前同事这个更新逻辑里,做了全字段更新,也就是定时任务启动查出来的failed又覆盖写回这个表。
于是,我让小G先临时把master_cluster_status改对,再这个id更改成其他值,这样根据id做update时报错,后面再改回原id,观察了几个轮回,update时间有变,不会再刷回脏数据
定时任务为啥会这么久
查看了表里数据,容灾任务大概80个,发现调用华为云api,部分站点会需要几秒(例如北方的乌兰察布区域)整个过程算下来跑完需要5分钟以上
又上去看了这个定时任务的配置,发现之前同事配置3分钟一次,把它调整到8分钟(临时调,观察是否有其他副作用)
故事结束
定时任务有长事务,可能导致脏数据回写,可采用乐观锁加版本号解决。同时使用框架调用时,尽量不硬编码,未修改的字段不要覆盖set回原表